AVL Tree & Splay Tree
AVL Tree
Splay Tree
Red-Black Tree & B+ Tree
Red-Black Tree
节点定义
typedef struct BRTNode{
struct BRTNode * parent;
struct BRTNode * left;
struct BRTNode * right;
int key;
int color;// 1 for red and 0 for black
}
规则
- 节点非黑即红
- 根节点一定是黑色
- 叶子节点(NIL)一定是黑色,这里 叶子节点 指的是 NULL 指针指向的节点
- 每个红色节点的两个子节点都为黑色,(也说明红色节点的父亲节点一定也为黑色)
- 从任一节点到其每个叶子节点(NIL)的所有简单路径,都包含相同数目的黑色节点(黑色完美平衡)
- 这个黑色节点数成为节点 X 的黑高,记为 $bh(X)$
红黑树的保持平衡的操作
左旋、右旋、变色
Insertion
首先默认插入节点 n 为红色
-
按照 BST 的插入操作进行插入(这里不要进行变色操作)
-
插入节点成为根节点:将节点染成黑色
-
插入节点不是根节点
-
插入节点的父节点 p 为黑色:无需任何调整,只要直接插入就好
-
插入节点的父节点 p 为红色(那么这个父节点一定不是根节点,所以一定会存在祖父节点 g ,且 g 一定为黑色节点)
-
父节点 p 和叔叔节点 u(uncle)均为红色
-
p 和 u 变为黑色
- g 变为红色
- 若 g 的父节点为黑色,则调整结束
- 若 g 的父节点为红色,则将 g 作为当前插入节点继续向上调整,直到某次调整祖父节点的父节点为黑色

-
父节点 p 为红色,叔叔节点 u 为黑色(此时根据 g p n 三者的位置关系又有四种情况)
-
[x] LL型
- p 变黑色,g 变红色
- 右旋 g
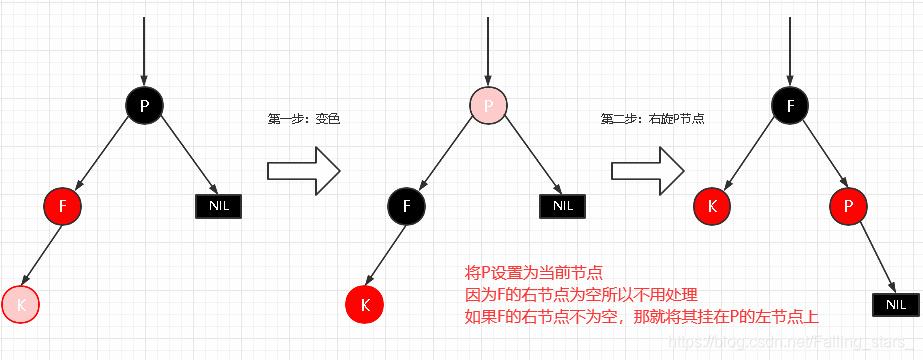
-
[x] RR型
- p 变黑色,g 变红色
- 左旋 g

-
[x] LR型
- 左旋 p
- 将 p 视为新插入节点,变为 LL 型

-
[x] RL型
- 右旋 p
- 将 p 视为新插入节点,变为 RR 型

-
Deletion
记:删除节点为 n(now), 替代 n 的后代节点为 d(descendant)。
- 按照 BST 的删除操作进行删除(这里不要进行变色操作)
- n 度 0 :将父节点指向它的指针置为 NULL,可以理解为用 n 的子节点 NIL 替代 n 。
- n 度 1 :用它的子节点 d 替代它
-
n 度 2 :找到左子树最大或者右子树最小节点 d 的值替代 n 的值,删除 d 节点
- 此情况也会退化成删除度为 0 或者 1 的节点的情况,所以仅考虑前两种情况
-
如果 n 为红色节点:两种情况均不需要做出变色操作
-
如果 n 为黑色节点:黑高发生变化,要变色和旋转
-
n 度 1
- n 的子节点 d 替代它
- 不管 d 之前什么颜色,都变成黑色
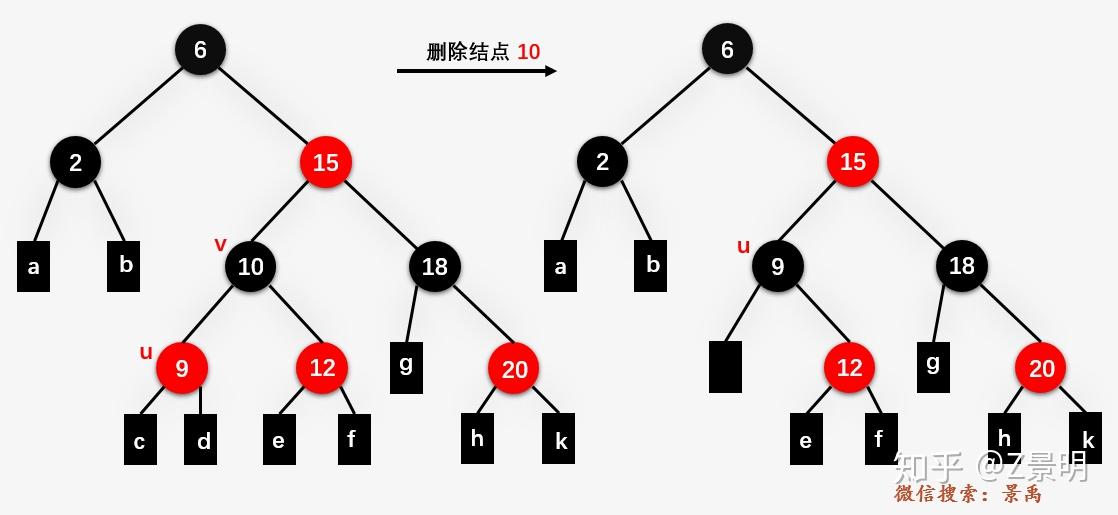
-
n 度 0 :这是一个相当相当复杂的情况
- 首先给出一个 双黑节点 的概念:当删除结点 n 是黑色结点,且它被它的黑色子节点 d 替换时,它的子结点 d 就被标记为 双黑节点。
通俗理解,删除一个黑色节点之后,某些路径上的黑高 bh 会减少 1 ,而在颜色的修复调整之前,为了抵消这个减少 1 的情况,我们就让替代节点 d 承担 2 个黑色,于是称为 “双黑节点”。而我们后续通过调整,各个路径上的黑高用平衡了,这时这个双黑节点也就不需要承担多余的 1 个黑色,于是它又变成了普通黑色节点。
我们不难发现,当 n 为黑色的度 0 节点时,删除 n 后用于替代 n 的后代节点 d 就是黑色的 NIL 叶子节点,所以这种情况下,d 一定是一个双黑节点。而删除操作本质就是 将这个双黑节点转化为普通黑色节点。
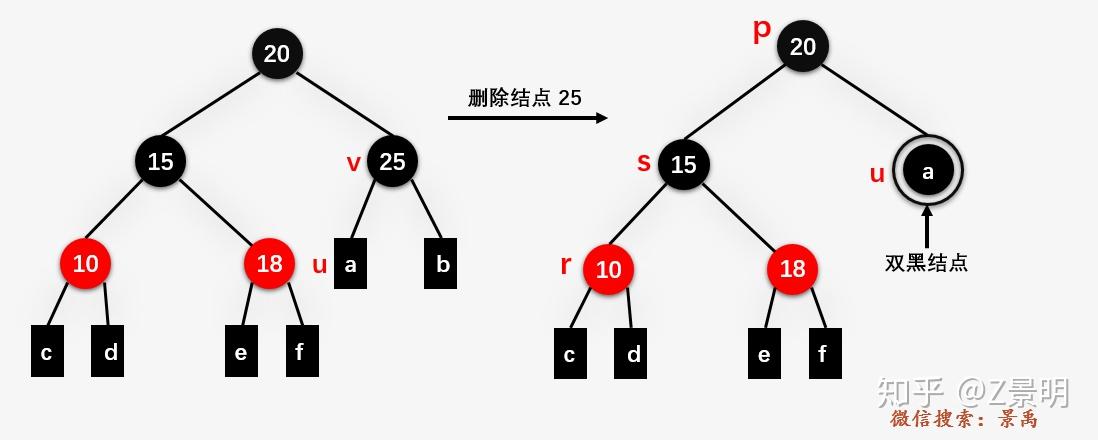
- case 1 : d 是根节点
直接变成普通黑色节点,其实也就是空树。
- case 2 :d 不是根节点
首先我们约定 d 的兄弟节点为 b(brother),b 的子节点为 c(cousin),u 和 b 的父节点为 p(parent)。
-
[x] 兄弟节点 b 为黑色且 b 至少有一个红色的子节点 c ,根据 p b c 的位置关系,就有 LL、LR、RL、RR 四种类型
-
LL 型
-
b 的颜色给 c,p 的颜色给 b
- 右旋 p
- 不管 p 之前什么颜色,p 都变成黑色

-
RR 型
-
b 的颜色给 c,p 的颜色给 b
- 左旋 p
-
不管 p 之前什么颜色,p 都变成黑色
-
LR 型
-
p 的颜色给 c
- 左旋 b
- 右旋 p
- 不管 p 之前什么颜色,p 都变成黑色

-
RL 型
-
p 的颜色给 c
- 右旋 b
- 左旋 p
- 不管 p 之前什么颜色,p 都变成黑色
-
-
[x] 兄弟节点 b 为黑色且 b 的两个子节点都是黑色 (递归处理)
-
如果双黑节点 d 的父亲节点 p 为红色
-
将 b 设置为红色
- 将 p 设置为黑色
- d 成为普通黑色节点

-
如果双黑节点 d 的父亲节点 p 为黑色
-
将 b 设置为红色
- 将 p 设置为双黑节点
- d 成为普通黑色节点
- 递归地对新的双黑节点 p 进行上述调整,直到遇到一个父节点为红色,然后按前一种情况进行调整即可完成

-
-
[x] 兄弟节点 b 为红色
-
b 为 p 的左儿子
-
右旋 p
- p 和 b 变成与之前相反的颜色
- 此时 d 的父兄情况发生了改变,根据新的情况重新判断应该采取怎样的调整的方式

-
b 为 p 的右儿子
-
左旋 p
- p 和 b 变成与之前相反的颜色
- 此时 d 的父兄情况发生了改变,根据新的情况重新判断应该采取怎样的调整的方式

-
B+ Tree
提出一个重要概念——阶
性质
一棵 M 阶的 B+ 树有以下性质:
- 根节点要么是叶节点(没有儿子),要么有 $[2,M]$ 个孩子
- 除了根节点以外的非叶节点有 $[\lceil\frac M2\rceil,M]$ 个孩子
- 所有叶节点都在同一层
结构
叶节点:有序存放关键字
非叶节点:存放索引,便于快速定位
索引需要根据子树的叶节点来确定,一般是从 第二子树 开始的每一棵子树的叶节点中的 最小值

Insertion
- 若 被插入关键字 所在的节点含有的关键字数目小于阶数 M,则直接插入
- 若 被插入关键字 所在的节点含有的关键字数目等于阶数 M,则需要将该结点分裂为两个节点,一个包含 $⌈\frac M2⌉$ 个关键词,另一个包含 $M+1-\lceil\frac M2\rceil$ 个关键字。同时,将大的节点中最小的关键字上移至其父亲节点。
- 若 父亲节点 中包含的关键字个数小于 M-1,则插入操作完成
- 若 父亲节点 中包含的关键字个数等于 M-1,则应继续分裂父亲节点
- 如果父亲节点已经是根节点,则需要重新创建一个根节点
Deletion
- 若 要删除关键字 所在的节点含有的关键字数目大于 $⌈\frac M2⌉$ ,则可以直接删除
- 若删除的刚好是该节点的最小值,则需要注意更改父亲节点的索引
- 若 要删除关键字 所在的节点含有的关键字数目等于 $⌈\frac M2⌉$ ,则删除后需要调整
- 若该节点的兄弟节点中含有多余的关键字,可以从兄弟节点中取关键字到该节点来 补位 ,然后可能要更改父亲节点中的索引
- 若该节点的兄弟节点没有多余的关键字,则需要将该节点与它的一个兄弟结点 合并 ,然后可能要更改父亲节点中的索引
- 合并操作可能会导致 父亲节点无需存在,那么需要依照以上规律 处理其双亲结点
Inverted File Index
如何理解文档
$TF-IDF$ models
用于衡量该文档对该关键词讲解的
$TF$ (term frequency) : the number of times a word occurs in a document
$DF$ (document frequency) : the number of documents that contain the word
mathematical model : $\frac{TF}{\log{(IDF)}}$
- $IDF$ : inverted $DF$
- use logarithm for DF is extremely numerous
n-gram : see n words a time
Transformer
Inverted File Index
Inverted:由一个词指向包含它的文档(正常搜索逻辑是从文档再到词语)
结构
$
- $Times$:该词在该文档中出现的次数
为什么保留 Times:进行按位与操作前先根据times排序
-
$I_{document}$:该词出现的文档序号
-
$P_{word_ place}$:该词出现在文档中的词序

具体操作
Term Reading
-
word stemming 处理后缀 : Porter's stemmer
-
stop words
Term Accessing
- search tree
- hash
Dynamic indexing
Compression:除去 stop word;利用差分方式记录数据
Relevancy of the Answer Set
- precision:精确率
- recall:找回率